您现在的位置是:网站首页>文章详情文章详情
DUEditor修复远程图片抓取和图片在线搜索
![]() inlike2021-10-20【
原创文章
】
浏览(2512)
评论(0)
喜欢(15)
inlike2021-10-20【
原创文章
】
浏览(2512)
评论(0)
喜欢(15)
简介DUEditor是一款功能丰富的富文本编辑器,但是由于项目推出比较久了,并且后续无人维护,因此很多实用的功能都出现了失效的情况。本次修复了两个问题,一个是粘贴文章中的图片不能抓取到本地保存的问题,另一个是不能使用百度在线的图片搜索功能。对于一个强迫症来说,这两个功能非常有必要,因为本博客的设计之初,就定位于丰富的图文博客,包括封面都是可以设置并显示四张封面图。

DUEditor是一款功能丰富的富文本编辑器,但是由于项目推出比较久了,并且后续无人维护,因此很多实用的功能都出现了失效的情况。本次修复了两个问题,一个是粘贴文章中的图片不能抓取到本地保存的问题,另一个是不能使用百度在线的图片搜索功能。对于一个强迫症来说,这两个功能非常有必要,因为本博客的设计之初,就定位于丰富的图文博客,包括封面都是可以设置并显示四张封面图。
粘贴文章中的图片不能保存到本地,带来的问题是出现防盗链,复制过来的文章不显示,此前解决这个问题需要手动截图然后粘贴上传替换原来的图片,如果能够恢复远程图片抓取功能,在效率是能提升很多。
百度图片搜索是必要的功能,每一篇文章的配图都在通过百度搜索许多关键词,修复在线图片搜索功能,可以直接插入选择图片,并保存抓取到本地文件夹下。

修复远程图片抓取到本地功能
首先参照https://github.com/fex-team/ueditor/commit/9089cfaa5745f629680aea2912efeb108f9c368b修改前端的JavaScript代码,该地址对应的代码文件路径是/static/ueditor/ueditor.all.min.js,按照说明修改即可。
远程图片抓取本地,处理过程有点模糊,这里大致记录一下。当粘贴内容存在远程图片时,会发送抓取请求,这一步没有问题,该请求会交给DUEditor插件下的view.py中的catcher_remote_image视图函数处理,其源码如下:
mime2type = {}
mime2type["image/gif"]="gif"
mime2type["image/jpeg"]="jpg"
mime2type["image/png"]="png"
mime2type["image/bmp"]="bmp"
mime2type["image/webp"]="webp"
@csrf_exempt
def catcher_remote_image(request):
"""远程抓图,当catchRemoteImageEnable:true时,
如果前端插入图片地址与当前web不在同一个域,则由本函数从远程下载图片到本地
"""
if not request.method=="POST":
return HttpResponse(json.dumps( u"{'state:'ERROR'}"),content_type="application/javascript")
state="SUCCESS"
allow_type= list(request.GET.get("catcherAllowFiles",USettings.UEditorUploadSettings.get("catcherAllowFiles","")))
max_size=int(request.GET.get("catcherMaxSize",USettings.UEditorUploadSettings.get("catcherMaxSize",0)))
remote_urls=request.POST.getlist("source[]",[])
print(remote_urls)
catcher_infos=[]
path_format_var=get_path_format_vars()
for remote_url in remote_urls:
#取得上传的文件的原始名称
remote_file_name=os.path.basename(remote_url)
remote_original_name,remote_original_ext=os.path.splitext(remote_file_name)
#文件类型检验
if len(remote_original_ext)==0 or remote_original_ext in allow_type:
path_format_var.update({
"basename":remote_original_name,
"extname":remote_original_ext[1:],
"filename":get_filename(request.user),
"user_dir": str(request.user.id),
})
#读取远程图片文件
try:
remote_image=urllib.request.urlopen(remote_url)
except Exception as E:
state = u"抓取图片错误:%s" % E.message
#将抓取到的文件写入文件
if len(remote_original_ext) == 0:
if "Content-Type" in remote_image.headers and remote_image.headers["Content-Type"] in mime2type :
path_format_var.update({
"extname": mime2type[remote_image.headers["Content-Type"]],
})
else:
state = u"不能判断抓取图片文件后缀"
tempPath = 'temp/{filename}.{extname}'.format(**path_format_var)
# 计算临时本地保存的文件名,临时本地保存主要是为阿里云OSS此类的的Storage准备的
o_filename = os.path.join(settings.MEDIA_ROOT, tempPath).replace("\\", "/")
with open(o_filename, 'wb') as f:
f.write(remote_image.read())
f.close()
filesize = os.path.getsize(o_filename)
if max_size != 0:
from .utils import FileSize
MF = FileSize(max_size)
if filesize > MF.size:
state = u"上传文件大小不允许超过%s。" % MF.FriendValue
os.remove(o_filename)
fileurl=""
if state == "SUCCESS":
# 取得输出文件的路径
path_format = USettings.UEditorUploadSettings["catcherPathFormat"]
OutputPath = path_format.format(**path_format_var)
with open(o_filename, 'rb') as f:
filepath = save_upload_file(f, OutputPath)
fileurl = default_storage.url(filepath)
os.remove(o_filename)
catcher_infos.append({
"state":state,
"url":fileurl,
"size":filesize,
"title":remote_original_name,
"original":remote_file_name,
"source":remote_url
})
return_info={
"state":"SUCCESS" if len(catcher_infos) >0 else "ERROR",
"list":catcher_infos
}
return JsonResponse(return_info)出现问题的是with open(o_filename, 'wb') as f这句,原因是找不到/media/temp目录,检查对应文件夹下并没有该路径,因此导致保存图片失败,解决方式是在media文件夹下创建temp文件。
创建后再次尝试,抓取远程图片功能正常,但是粘贴微信文章时,文章中的图片也不能保存到本地,通过调试发现微信中的图片格式是webp,不在保存范围内,因此上述源码的第6行添加了对webp格式的支持。
修复图片搜索功能
修复图片搜索功能,遇到两个问题,第一个是图片搜索使用的接口失效,另一个是将搜索图片插入正文中补鞥呢保存到本地,第二个问题还是在第一处修改。
原来使用的接口是:
url = "http://image.baidu.com/i?ct=201326592&cl=2&lm=-1&st=-1&tn=baiduimagejson&istype=2&rn=32&fm=index&pv=&word=" + _this.encodeToGb2312(key) + type + "&keeporiginname=" + keepOriginName + "&" + +new Date;不过这个接口失效了,返回错误数据,因此在线搜索功能用不了。首先使用第一种方式来尝试解决,分析了新的百度图库搜索接口,但是遇上跨域问题,还想并不支持在其他域名下使用。就只剩下第二种方式,通过后台提供搜索接口,然后后台再将从百度获取到的数据返回前端。
在urls中添加一条路由,用于返回图片数据,返回图片数据应该是这种格式:
{
'data': [
{
'fromPageTitleEnc': 'disc性格测试及全面分析ppt',
'objURL': 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.51wendang.com%2Fpic%2F5e256164e2d1b3a9c67b6a2d%2F6-810-jpg_6-1170-0-0-1170.jpg&refer=http%3A%2F%2Fwww.51wendang.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1637318641&t=e13f99008d389d8dd9cb8a429c6aa14f',
'fromURL': 'http://www.51wendang.com/doc/5e256164e2d1b3a9c67b6a2d/6'
},
{
'fromPageTitleEnc': '电视测试屏幕矢量插画',
'objURL': 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fphoto.16pic.com%2F00%2F45%2F78%2F16pic_4578762_b.jpg&refer=http%3A%2F%2Fphoto.16pic.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1637318641&t=a0bd21983724461b0cfa34e8e091ca9c',
'fromURL': 'http://m.16pic.com/vector/pic_4578762.html'
},
{
'fromPageTitleEnc': 'ddr5来了也不怕可稳定工作在ddr45066的钻石内存实战测试',
'objURL': 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwx3.sinaimg.cn%2Flarge%2F0023oFOyly1gva1b1n0c3j612w0jdq4u02.jpg&refer=http%3A%2F%2Fwx3.sinaimg.cn&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1637318641&t=eb6130226191869fbd9be75d12291996',
'fromURL': 'http://weibo.com/ttarticle/p/show?id=2309404690710954902041'
},
{
'fromPageTitleEnc': '全新 眼镜验光设备 17寸液晶视力表方屏 视力测试仪器投影仪',
'objURL': 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.china.alibaba.com%2Fimg%2Fibank%2F2015%2F644%2F579%2F2089975446_333543422.jpg&refer=http%3A%2F%2Fimg.china.alibaba.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1637318641&t=848c41df5408eed0737918161a9652fe',
'fromURL': 'http://tz.lshou.com/shangjia/c2377145226/tce9edb991a8.html'
}
]
}三个字段都是从新的图库接口获取的,但是objURL、fromURL这两个字段还需要经过解密才能获取数据,分别是图片的下载地址和图片来源的链接,解密函数百度一下就有。
开始修改,在urls.py文件中加入一条新路由用于返回图片数据:
url('getImageData', getImageData)在Django APP的view.py文件中加入对应的视图函数:
def decode_url(url):
"""
对百度加密后的地址进行解码\n
:param url:百度加密的url\n
:return:解码后的url
"""
table = {'w': "a", 'k': "b", 'v': "c", '1': "d", 'j': "e", 'u': "f", '2': "g", 'i': "h",
't': "i", '3': "j", 'h': "k", 's': "l", '4': "m", 'g': "n", '5': "o", 'r': "p",
'q': "q", '6': "r", 'f': "s", 'p': "t", '7': "u", 'e': "v", 'o': "w", '8': "1",
'd': "2", 'n': "3", '9': "4", 'c': "5", 'm': "6", '0': "7",
'b': "8", 'l': "9", 'a': "0", '_z2C$q': ":", "_z&e3B": ".", 'AzdH3F': "/"}
url = re.sub(r'(?P<value>_z2C\$q|_z\&e3B|AzdH3F+)', lambda matched: table.get(matched.group('value')), url)
return re.sub(r'(?P<value>[0-9a-w])', lambda matched: table.get(matched.group('value')), url)
def getImageData(request):
if not request.user.is_authenticated:
return HttpResponse(status=404)
import requests
url = "https://image.baidu.com/search/acjson?"
word = request.GET.get("searchTxt", "python")
page = request.GET.get("page", "1")
payload = {'tn': 'resultjson_com',
'ipn': 'rj',
'word': word,
'pn': int(page) * 60,
'rn': '60'
}
headers = {'Accept': 'text/plain, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Host': 'image.baidu.com',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDQsNiwxLDUsMiw4LDcsOQ%3D%3D&word=%E7%99%BE%E5%BA%A6%E5%9B%BE%E7%89%87%E7%88%AC%E8%99%AB',
'sec-ch-ua': '"Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'}
r = requests.get(url, params=payload, headers=headers)
data = r.json()['data']
items = []
for i in data:
try:
item = {"fromPageTitleEnc": i['fromPageTitleEnc'], "objURL": decode_url(i['objURL']),
"fromURL": decode_url(i['fromURL'])}
except:
continue
items.append(item)
return JsonResponse({"data": items}) # 返回json数据通过简化接口返回前60张图片,目前不支持翻页,但是可以通过接口的参数来限制图片的尺寸,并且未实现该功能。
修改前端js,在线图片对应的前端js文件是\static\ueditor\dialogs\image\image.js,原文件内容如下:
getImageData: function(){
var _this = this,
key = $G('searchTxt').value,
type = $G('searchType').value,
keepOriginName = editor.options.keepOriginName ? "1" : "0",
url = "http://image.baidu.com/i?ct=201326592&cl=2&lm=-1&st=-1&tn=baiduimagejson&istype=2&rn=32&fm=index&pv=&word=" + _this.encodeToGb2312(key) + type + "&keeporiginname=" + keepOriginName + "&" + +new Date;
$G('searchListUl').innerHTML = lang.searchLoading;
ajax.request(url, {
'dataType': 'jsonp',
'charset': 'GB18030',
'onsuccess':function(json){
var list = [];
if(json && json.data) {
for(var i = 0; i < json.data.length; i++) {
if(json.data[i].objURL) {
list.push({
title: json.data[i].fromPageTitleEnc,
src: json.data[i].objURL,
url: json.data[i].fromURL
});
}
}
}
_this.setList(list);
},
'onerror':function(){
$G('searchListUl').innerHTML = lang.searchRetry;
}
});
},
/* 添加图片到列表界面上 */修改后的文件内容:
getImageData: function () {
var _this = this,
key = $G('searchTxt').value,
type = $G('searchType').value,
keepOriginName = editor.options.keepOriginName ? "1" : "0",
// url = "http://image.baidu.com/i?ct=201326592&cl=2&lm=-1&st=-1&tn=baiduimagejson&istype=2&rn=32&fm=index&pv=&word=" + _this.encodeToGb2312(key) + type + "&keeporiginname=" + keepOriginName + "&" + +new Date;
// url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8075218573520344119&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%99%BE%E5%BA%A6%E5%9B%BE%E7%89%87%E7%88%AC%E8%99%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%99%BE%E5%BA%A6%E5%9B%BE%E7%89%87%E7%88%AC%E8%99%AB&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&nojc=&pn=150&rn=30&gsm=96&1634712206467=';
url = '/getImageData?searchTxt=' + key + "&page=1"
$G('searchListUl').innerHTML = lang.searchLoading;
ajax.request(url, {
'dataType': 'json',
"method":'get',
// 'charset': 'GB18030',
'onsuccess': function (json) {
var json = JSON.parse(json.response)
var list = [];
if (json && json.data) {
for (var i = 0; i < json.data.length; i++) {
if (json.data[i].objURL) {
list.push({
// title: json.data[i].fromPageTitleEnc,
// src: json.data[i].objURL,
// url: json.data[i].fromURL
title: json.data[i].fromPageTitleEnc,
src: json.data[i].objURL,
url: json.data[i].fromURL
});
}
}
}
_this.setList(list);
},
'onerror': function () {
$G('searchListUl').innerHTML = lang.searchRetry;
}
});
},修改完成,实现在线搜索图片的功能,也能单选或者多选插入图片,但是图片不能保存到本地。

图片不能保存到本地的原因,是因为百度返回的链接中含有来源的地址信息,在catcher_remote_image视图函数解析时,不能解析出其后缀,导致下载失败。处理该方法是手动解析,并且给一个异常情况下的默认格式,这个格式不是最后的图片后缀,而是请求图片时在返回的响应头的获取图片类型。修改后源码如下:
mime2type = {}
mime2type["image/gif"] = "gif"
mime2type["image/jpeg"] = "jpg"
mime2type["image/png"] = "png"
mime2type["image/bmp"] = "bmp"
mime2type["image/webp"] = "webp"
@csrf_exempt
def catcher_remote_image(request):
"""远程抓图,当catchRemoteImageEnable:true时,
如果前端插入图片地址与当前web不在同一个域,则由本函数从远程下载图片到本地
"""
if not request.method == "POST":
return HttpResponse(json.dumps(u"{'state:'ERROR'}"), content_type="application/javascript")
state = "SUCCESS"
allow_type = list(
request.GET.get("catcherAllowFiles", USettings.UEditorUploadSettings.get("catcherAllowFiles", "")))
max_size = int(request.GET.get("catcherMaxSize", USettings.UEditorUploadSettings.get("catcherMaxSize", 0)))
remote_urls = request.POST.getlist("source[]", [])
print(remote_urls)
catcher_infos = []
path_format_var = get_path_format_vars()
for remote_url in remote_urls:
# 取得上传的文件的原始名称
remote_file_name = os.path.basename(remote_url)
remote_original_name, remote_original_ext = os.path.splitext(remote_file_name)
if 'gimg2.baidu.com/image_search' in remote_url:
try:
from urllib.parse import quote, unquote
bd_url = unquote(remote_url.split('src=')[-1]).split('&')[0]
remote_original_ext = '.' + bd_url.split('.')[-1]
except:
remote_original_ext = '.png'
# 文件类型检验
if len(remote_original_ext) == 0 or remote_original_ext in allow_type:
path_format_var.update({
"basename": remote_original_name,
"extname": remote_original_ext[1:],
"filename": get_filename(request.user),
"user_dir": str(request.user.id),
})
# 读取远程图片文件
try:
remote_image = urllib.request.urlopen(remote_url)
except Exception as E:
state = u"抓取图片错误:%s" % E.message
# 将抓取到的文件写入文件
if len(remote_original_ext) == 0:
if "Content-Type" in remote_image.headers and remote_image.headers["Content-Type"] in mime2type:
path_format_var.update({
"extname": mime2type[remote_image.headers["Content-Type"]],
})
else:
state = u"不能判断抓取图片文件后缀"
tempPath = 'temp/{filename}.{extname}'.format(**path_format_var)
# 计算临时本地保存的文件名,临时本地保存主要是为阿里云OSS此类的的Storage准备的
o_filename = os.path.join(settings.MEDIA_ROOT, tempPath).replace("\\", "/")
with open(o_filename, 'wb') as f:
f.write(remote_image.read())
f.close()
filesize = os.path.getsize(o_filename)
if max_size != 0:
from .utils import FileSize
MF = FileSize(max_size)
if filesize > MF.size:
state = u"上传文件大小不允许超过%s。" % MF.FriendValue
os.remove(o_filename)
fileurl = ""
if state == "SUCCESS":
# 取得输出文件的路径
path_format = USettings.UEditorUploadSettings["catcherPathFormat"]
OutputPath = path_format.format(**path_format_var)
with open(o_filename, 'rb') as f:
filepath = save_upload_file(f, OutputPath)
fileurl = default_storage.url(filepath)
os.remove(o_filename)
catcher_infos.append({
"state": state,
"url": fileurl,
"size": filesize,
"title": remote_original_name,
"original": remote_file_name,
"source": remote_url
})
return_info = {
"state": "SUCCESS" if len(catcher_infos) > 0 else "ERROR",
"list": catcher_infos
}
return JsonResponse(return_info)到此就修复了远程图片抓取、微信内图片抓取、在线图片搜索、在线图片本地保存的问题。

相关文章



本栏推荐
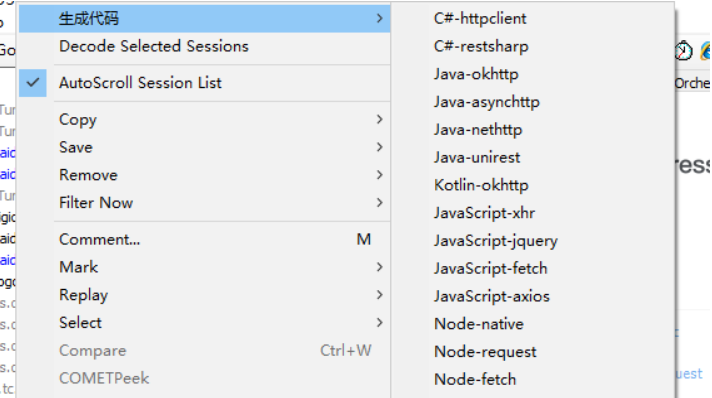 Fiddler请求生成代码插件
Fiddler请求生成代码插件






标签云
猜你喜欢

站点信息
- 建站时间:2019-5-24
- 网站程序:like in love
- 主题模板:《今夕何夕》
- 文章统计:104条
- 文章评论:***条
- 微信公众号:扫描二维码,关注我们
